iPhone 17 Pro Ran a 400B LLM. Here's How.
A 400B parameter LLM on iPhone 17 Pro via SSD-to-GPU streaming. How Flash-MoE works, why on-device AI matters for privacy.

A developer just ran a 400-billion parameter large language model on an iPhone 17 Pro. Not on a server. Not through an API. Directly on the phone, with airplane mode on.
The model is called Flash-MoE, an open-source project by @anemll. It generates text at 0.6 tokens per second — roughly one word every two seconds. That's glacially slow compared to cloud inference. But the fact that it runs at all on a device with 12GB of RAM is a genuine engineering breakthrough, and it signals something much bigger for the future of mobile AI.
This story hit Hacker News and sparked a heated debate about what "running" an LLM actually means, whether this is a stunt or a genuine preview of the future, and how far mobile hardware still needs to go. Let's break down what actually happened, how it works, and why it matters — even at 0.6 tokens per second.
What Happened: Flash-MoE on iPhone 17 Pro
The demo, posted by developer @anemll on Twitter, shows an iPhone 17 Pro running a 400B parameter Mixture of Experts (MoE) model entirely on-device. No cloud. No internet. Just the phone's A19 Pro chip and its internal flash storage.
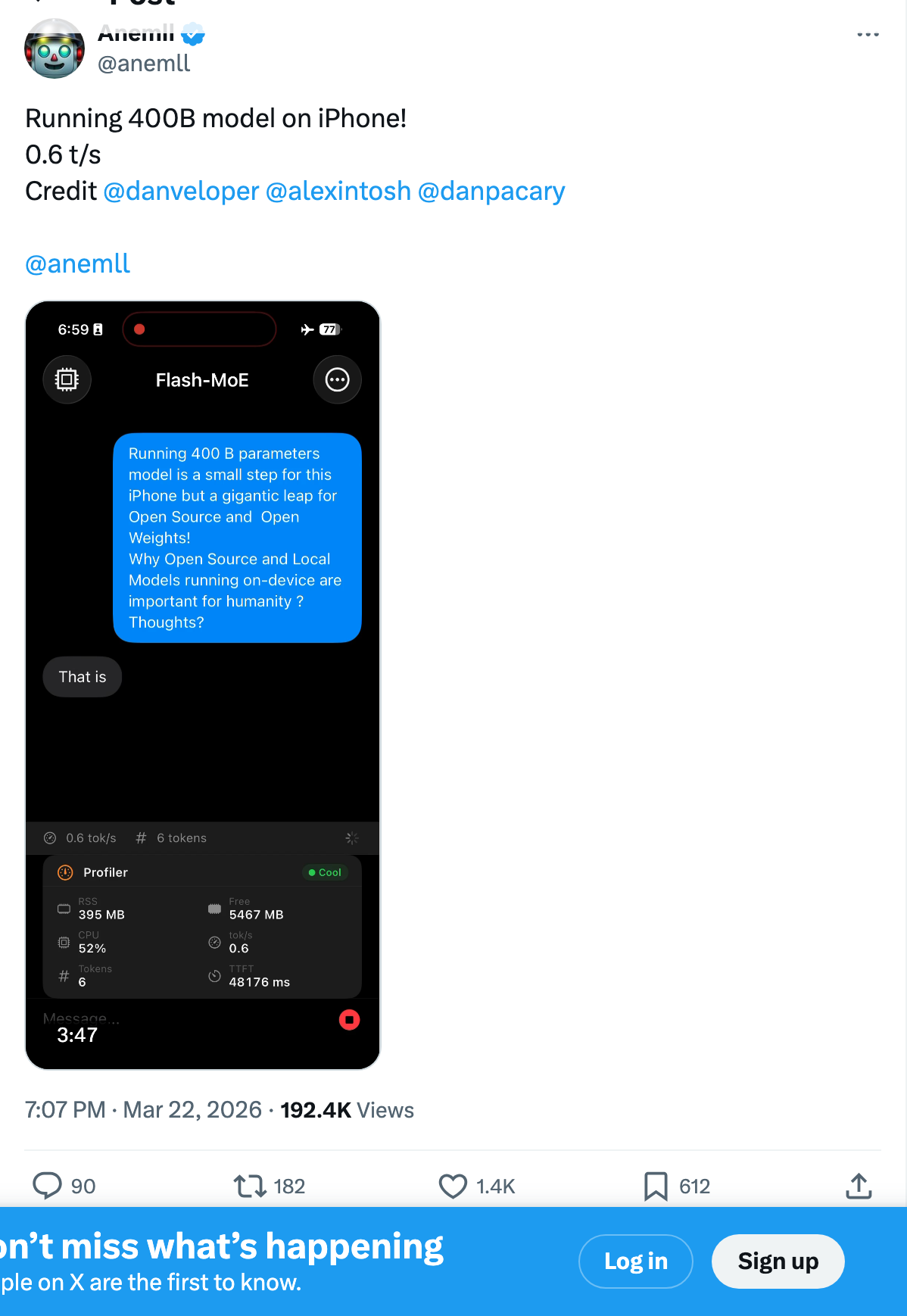
The key insight: this isn't a dense 400B model. The model is specifically Qwen3.5-397B-A17B — 397 billion total parameters, but only 17 billion active per token. It's a Mixture of Experts architecture with 512 experts per layer, where only 11 experts are activated for each token (10 routed plus 1 shared expert). That means the phone never needs to hold all 400B parameters in memory at once — just the small fraction that's actively computing.
Here's how the system works:
- SSD-to-GPU streaming (SSD offloading). Instead of loading the entire model into RAM (impossible with 12GB), Flash-MoE streams model weights from the phone's fast NVMe storage directly to the GPU as needed.
- Mixture of Experts routing. The MoE architecture determines which expert sub-networks are needed for each token, then loads only those experts from storage.
- Quantization. The model weights are aggressively compressed to reduce the data that needs to be transferred per expert.
- Expert prefetching (windowing). Apple's "LLM in a Flash" research showed that consecutive tokens often activate similar experts. By keeping recently-used experts in RAM and only loading cold ones from storage, the system dramatically reduces redundant SSD reads.
The speed bottleneck comes down to bandwidth math: the iPhone's LPDDR5X RAM delivers approximately 51 GB/s, but the NVMe SSD tops out at roughly 4-6 GB/s. That 10x gap is the entire speed explanation — each token requires loading expert weights from SSD, and SSD bandwidth is the ceiling. The result is a system that trades speed for capability. You get a massive, highly capable model running on a phone — but you wait for it.
Glen Rhodes' deep dive covers the flash-based inference streaming technique in detail, including how the same approach works on MacBook hardware:
The Apple "LLM in a Flash" Connection
This demo didn't come out of nowhere. It builds directly on Apple's December 2023 research paper, "LLM in a Flash: Efficient Large Language Model Inference with Limited Memory", which laid out the theoretical framework for flash-based inference — running models larger than available RAM by intelligently streaming data from flash storage.
Tech journalist Max Weinbach captured the skepticism when the paper first dropped in 2023 — a skepticism that Flash-MoE has now answered:
The paper proposed two key innovations:
- Windowing — reusing recently activated neurons to reduce data transfer. Since consecutive tokens often activate similar experts, you can keep hot experts in RAM and only load cold ones from storage.
- Row-column bundling — reading larger, contiguous chunks from flash storage rather than many small random reads. Flash storage is fast for sequential reads but slow for random access. Bundling expert weights into contiguous blocks makes the read pattern SSD-friendly.
Apple's research showed that these techniques could enable running models up to 2x the available DRAM on an Apple M-series chip, with 4-5x faster inference on CPU and 20-25x faster on GPU compared to naive loading. Flash-MoE extends this approach further — to a model that's roughly 17x larger than the iPhone's RAM — by combining it with MoE's inherent sparsity.
TurboQuant: Solving the Other Memory Bottleneck
Flash-MoE tackles one half of the memory problem — streaming model weights from SSD so they don't all need to live in RAM. But there's a second bottleneck: the KV cache. Every token the model generates adds key-value entries to a cache that must remain in RAM for the model to maintain context. As conversations grow, this cache can consume gigabytes of precious DRAM that the active expert weights also need.
Google's TurboQuant paper (ICLR 2026, arxiv 2504.19874) directly addresses this. The technique compresses KV cache entries to achieve 6x memory reduction at zero accuracy loss — meaning a conversation that would normally consume 6GB of KV cache fits in just 1GB. Critically, TurboQuant requires no fine-tuning and can be applied retroactively to any existing model.
The combination is elegant: Flash-MoE solves the weight bottleneck (streaming experts from SSD), while TurboQuant solves the cache bottleneck (compressing KV entries in RAM). Together they address both memory constraints simultaneously — exactly the pair of techniques needed to make large models viable on memory-constrained devices like smartphones.
Why On-Device AI Matters (Even When It's Slow)
The Hacker News thread was split. Some saw this as a meaningless stunt — "0.6 tokens per second isn't running a model, it's torturing one." Others saw the trajectory: a year ago, this was literally impossible.
Here's why the trajectory matters more than the current speed:
The Butler vs. The Consultant
Think about what your phone actually knows about you. Your messages — years of conversations with partners, friends, family, colleagues. Your photos — every face you've captured, every place you've been, every meal, every moment. Your health data — resting heart rate trends, sleep patterns, blood oxygen, menstrual cycles, workout recovery. Your location history — where you live, where you work, which coffee shop you visit at 7:14 AM every Tuesday.
No other entity on Earth has that complete a picture of your life. Not Google. Not your doctor. Not your spouse. Your phone is the single most intimate computational device ever created.
That intimacy demands a different model architecture — not the smartest model, but the most trusted one. Your on-device AI is the personal butler: always in the room, deeply familiar with your preferences, anticipating your needs before you voice them. It knows your commute shifted by 15 minutes last week. It notices your resting heart rate has been creeping up for three days — potentially flagging an oncoming illness before you feel a single symptom. It recognizes that you always text your partner when your flight lands and drafts the message before you reach for the keyboard.
This butler doesn't need to be a genius. It needs to never leave the house.
This butler architecture requires more than just a local model — it needs system-level integration to feed personal context into the model. Apple is uniquely positioned here because they control both the hardware and the OS, giving them the ability to pipe Health data, Messages, Photos, and Calendar into an on-device model without any third-party middleware or privacy tradeoffs.
When you need raw intellectual horsepower — synthesizing a 50-page research paper, generating complex code, reasoning through a multi-step business problem — you call in the cloud consultant. A frontier model like GPT-5 or Claude Opus processes your specific task, returns the result, and moves on. The data you share with the consultant is task-specific: a document, a question, a code snippet. Not your entire life history, not your health records, not your 3 AM messages.
This is exactly the architecture Apple is building with Private Cloud Compute. On-device processing for personal context. Cloud inference for heavy reasoning — with cryptographic guarantees that Apple's servers can't retain or inspect your data. The concern isn't hypothetical: we've seen how cloud AI training data practices can erode trust, and how supply chain vulnerabilities in AI infrastructure create real exposure when everything runs through third-party servers.
But training on your data isn't the only risk — there's retaining it. Even when cloud AI providers promise not to use your conversations for training, they still store them. Your AI chat history is becoming the new search history: a permanent record accessible to courts, hackers, or future policy changes. In June 2025, a federal judge in NYT v. OpenAI ordered OpenAI to preserve and segregate all output log data — including chats users had already deleted. The order was partially lifted in October 2025, but the legal precedent is set: cloud-stored conversations are discoverable evidence. What never leaves your phone can never be subpoenaed from a server. The butler can't be compelled to testify.
⚖️ The retention reality: OpenAI retains chat conversations indefinitely until users manually delete them. "Temporary chat" mode still keeps data for 30 days. API logs are retained for 30 days. This isn't unique to OpenAI. Any cloud AI provider is subject to the same legal frameworks — just as Google search history is retained and subpoenaable, your AI conversations follow the same pattern. This is a structural vulnerability of cloud inference, not a critique of any single provider.
The Qwen3.5-397B model running on the iPhone 17 Pro matters not because it outperforms cloud models — it doesn't. It matters because a model of that class is powerful enough to serve as a genuinely capable personal butler. One that understands nuance, handles complex requests, and never phones home with your data.
🏠 The Hybrid AI Split:
On-device (the butler): personal context, health data, messages, photos, location, daily habits — never leaves your device
Cloud (the consultant): complex reasoning, deep research, creative generation — receives only task-specific data, not your life history
1. Privacy Without Compromise
The technical guarantee is straightforward: when an LLM runs on your device, zero data leaves the phone. No server round-trips, no retention policies, no third-party access. Your prompts, context, and results exist only in local memory and vanish when the process ends. For sensitive queries — medical questions, financial planning, legal advice — this isn't a policy promise you hope a provider honors. It's a physics guarantee enforced by the air gap between your phone and the internet. And unlike cloud conversations that persist on provider servers indefinitely — subject to court orders and data breaches alike — on-device inference leaves no trace once the session ends.
2. Offline Access
Cloud AI fails when you need it most — on a plane, in a dead zone, during a server outage. On-device AI works anywhere your phone does. As models get smaller and faster, always-available AI assistance becomes possible without any connectivity requirement.
3. Zero Marginal Cost
Every cloud AI query has a cost — either per-token pricing through an API, or a subscription fee. On-device inference is free after the initial hardware investment. For use cases that involve thousands of daily queries (on-device agents, automated workflows, continuous monitoring), the economics flip dramatically in favor of local inference.
4. Latency for Simple Tasks
For short, simple queries, on-device inference can actually be faster than cloud — no network round-trip, no queue, no cold start. When smaller, optimized models run locally for routine tasks and cloud handles the complex stuff, you get the best of both worlds.
Peter Diamandis highlighted this trend earlier this month, noting that China's open-weight models are already running on-device:

On-Device vs. Cloud: When Each Wins
This isn't an either/or story. The future of mobile AI is hybrid — local models for some tasks, cloud for others. Here's how the tradeoffs break down:
| Factor | On-Device AI | Cloud AI |
|---|---|---|
| Privacy | ✅ Complete — data never leaves device | ⚠️ Depends on provider policies |
| Offline | ✅ Works anywhere | ❌ Requires internet |
| Cost per query | ✅ Free after hardware | ⚠️ Per-token or subscription |
| Speed (current) | ❌ 0.6 t/s for large models | ✅ 50-200+ t/s |
| Model capability | ⚠️ Limited by device RAM/storage | ✅ No hardware constraints |
| Context window | ❌ Severely limited on mobile | ✅ 100K-1M+ tokens |
| Latency (simple) | ✅ No network round-trip | ⚠️ Network + queue overhead |
| Updates | ⚠️ Requires download | ✅ Always latest model |
The practical sweet spot in 2026: small, fast models running locally for routine tasks (autocomplete, quick questions, on-device agents doing simple classification) while cloud handles anything requiring deep reasoning, large context, or frontier-level capability.
If you're interested in running AI locally on desktop hardware — where you have more RAM, better GPUs, and fewer constraints — our guide to running LLMs on your own hardware covers the full setup with Ollama, LM Studio, and llama.cpp. The mobile story is different: tighter constraints, but higher stakes for privacy and availability.
What This Enables: The On-Device Agent Future
The 0.6 t/s speed is a red herring. Nobody is going to use a 400B model for interactive chat on an iPhone. The real story is what happens when you combine these techniques with smaller, purpose-built models that can actually run at usable speeds on mobile hardware.
Beyond Apple Intelligence: The Next Leap
Apple Intelligence already ships approximately 3B parameter on-device models that power Siri's natural language understanding, notification summarization, and Writing Tools across iPhone, iPad, and Mac. These models run entirely on the Neural Engine without touching Apple's servers. But 3B parameters is the floor, not the ceiling.
The Flash-MoE demo represents the next scaling frontier for Apple Intelligence — moving from small, task-specific on-device models to general-purpose reasoning that stays local. An on-device language model that handles complex requests — multi-step planning, contextual summarization, nuanced drafting — without any server round-trip would be faster, more private, and more reliable than today's approach.
Apple has been quietly building toward this. The A19 Pro's Neural Engine, combined with the "LLM in a Flash" techniques, suggests Apple is laying the groundwork for an Apple Intelligence that thinks locally first and only phones home for frontier-class tasks.
Private AI Assistants
Imagine an AI assistant that reads your email, manages your calendar, and drafts responses — all without your data ever leaving your phone. No Google reading your messages. No OpenAI storing your calendar. No Anthropic training on your email drafts. On-device models make this possible without sacrificing capability.
On-Device Agents
The current generation of AI agents runs in the cloud, with all the cost, latency, and privacy implications that entails. On-device agents that can browse your local files, interact with apps, and take actions — all without a network connection — represent the next frontier. The best AI coding assistants already show what's possible when AI has deep local context; mobile agents will extend this to your entire phone.
Apple's broader AI strategy, including the on-device innovations that make this possible, is covered in depth here:
The Technical Debate: Stunt or Breakthrough?
The Hacker News discussion reveals a genuine split in the technical community about what this demo means.
The skeptics make valid points. One commenter noted: "Ignore the 0.4 t/s, that's nothing. What really makes this example bullshit is the fact that there is no way the phone has enough RAM to hold any reasonable amount of context for that model." They're right — context window size is constrained by available RAM, and 12GB doesn't leave much room for KV cache after the active experts are loaded.
Another pointed out the fundamental physics: "Realistically you need 300+ GB/s fast access memory to the accelerator. You can gimmick a demo like this with an SSD, but the SSD is just not fast enough for anything more than showing off a neat trick."
The optimists counter that the trend line matters more than today's numbers. Someone observed: "A year ago this would have been considered impossible. The hardware is moving faster than anyone's software assumptions." Another noted the precedent from gaming: "The Unreal Engine Matrix demo for PS5 was streaming textures directly from SSD to the engine — the same principle applied to AI weights."
The pragmatists land somewhere in between: the Flash-MoE demo isn't a product. It's a proof of concept that validates the technique. The technique — SSD streaming of MoE experts — will become practical as storage gets faster, models get more efficient, and chips get more capable of managing the data pipeline.
What Developers Are Actually Running
The 400B demo grabbed headlines, but the developer community is already running practical models on iPhones at usable speeds. The same SSD offloading and MoE techniques, applied to smaller models, deliver results you can actually use.
On Reddit's r/LocalLLaMA — the largest community for local AI inference — developers report:
- Qwen3 4B running at ~25 tokens/second on A19 Pro via MLX — that's conversational speed
- SwiftAI enabling MLX-optimized LLMs on iOS through a simple API, with access to Apple's system intelligence models
- Significant energy efficiency gains on the A19 Pro GPU compared to previous generations
The open-source ecosystem is moving faster than Apple's official AI strategy. Tools like MLX (Apple's own ML framework), SwiftAI, and PocketPal are giving developers the building blocks for on-device AI apps today — without waiting for Apple to ship it through Siri.
ML engineer Maxime Labonne, whose posts reach 50M+ views on LinkedIn, called the Flash-MoE demo a validation of what the community has been building toward: MoE architectures are the unlock for running large-class intelligence on consumer hardware.
The Hardware Bottleneck: RAM Is Everything
The Hacker News thread surfaced a crucial tension in Apple's hardware strategy. One commenter laid it out clearly: "Apple has always seen RAM as an economic advantage — minimize memory, save billions in hardware costs. But AI requires copious amounts of fast working memory. Apple can't code their way around this."
The iPhone 17 Pro ships with 12GB of LPDDR5X RAM. For context:
- A quantized 7B model needs ~4GB — fits comfortably, with room for the OS and apps
- A quantized 14B model needs ~8GB — tight but doable
- A quantized 70B model needs ~40GB — not happening on current iPhones
- A quantized 400B model needs ~200GB — hence the SSD streaming workaround
For perspective, the same Qwen3.5-397B model runs at 19.98 tokens per second on an M4 Max MacBook Pro with 128GB of unified memory — 33x faster than the iPhone demo. That benchmark, reported in the Hacker News thread by the creator of Neovim, proves that Flash-MoE's SSD streaming technique scales beautifully when given more memory bandwidth. The 0.6 t/s on iPhone is a hardware constraint, not a fundamental limitation of the approach.
The real unlock for practical on-device AI isn't streaming 400B models from storage. It's Apple shipping iPhones with enough RAM to run 14B-30B models comfortably at 10-20 tokens per second. That would give users a genuinely capable local AI — one that rivals today's Claude, ChatGPT, and Gemini for everyday tasks — without any cloud dependency.
A semiconductor analyst on the Dwarkesh podcast recently predicted iPhones could increase in price by ~$250 due to increased RAM and chip costs from AI workloads. Whether Apple is willing to absorb or pass along that cost will determine how quickly on-device AI becomes a mainstream reality.
What Comes Next
The Flash-MoE demo is a waypoint, not a destination. Here's the trajectory to watch:
Near-term (2026-2027): Apple Intelligence evolves from today's 3B on-device models toward larger, more capable architectures. Siri gets smarter without sending more data to the cloud. Third-party apps gain access to on-device inference APIs. Small MoE models (7B-14B) run at 10-20 t/s on flagship phones.
Medium-term (2027-2028): iPhones ship with 16-24GB of RAM. On-device models handle most routine AI tasks at usable speeds. Cloud AI becomes the fallback for complex reasoning, not the default. The privacy argument becomes a marketing differentiator.
Long-term (2028+): The phone becomes the primary edge AI compute platform for personal tasks. Cloud handles training and frontier reasoning. Your private data stays private by default, not by policy. The gap between "runs on a phone" and "runs well on a phone" closes to the point where most users can't tell the difference.
The Bottom Line
A 400B LLM running at 0.6 tokens per second on an iPhone is a proof of concept, not a product. But it proves something important: the technique works. SSD-to-GPU streaming, MoE sparsity, and flash-attention optimizations can run models dramatically larger than available RAM on mobile hardware.
The practical implications are enormous. Not because anyone will chat with a 400B model on their phone at two seconds per word — but because these same techniques, applied to smaller models, will deliver genuinely useful AI that runs entirely on-device. Private. Offline. Free. No subscription, no API key, no data leaving your pocket.
Apple built the research foundation with "LLM in a Flash." The open-source community is proving it works in practice. The hardware is getting faster every year. The question isn't whether powerful on-device AI is coming to your phone. It's whether it arrives in 2027 or 2028.
For now, if you want to run AI locally today, your best bet is desktop hardware. Check our guide to running LLMs locally for practical setups that work right now — not in two seconds per word, but in real-time.
📺 Want the visual breakdown? We covered the full technical stack — Flash-MoE mechanics, TurboQuant, and the butler vs consultant framing — in video:
🎧 Deep Dive: Video Overview
Want a more immersive, cinematic breakdown? This AI-generated deep dive covers the hardware engineering, memory architecture, and thermal constraints in depth:
Sources: @anemll on Twitter, Hacker News discussion, Apple "LLM in a Flash" research, WCCFTech coverage, Glen Rhodes — Flash-Based Inference Streaming, r/LocalLLaMA discussions on iPhone AI inference, Maxime Labonne on LinkedIn
About ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
💬 Join the Discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related Articles
DeepClaude: Run Claude Code on DeepSeek for 90% Less
DeepClaude swaps Claude Code's backend to DeepSeek V4 Pro with 4 env vars. The setup, the real quality tradeoff, and when to switch back.
Inside the Claude Code Post-Mortem: 50+ Fixes, Verified
Anthropic shipped 50+ fixes across four CLI releases. We group them by category and give you a 5-minute self-test to verify the rebound.
Claude Code Charges Extra for 'OpenClaw' Git Commits
If your git history mentions OpenClaw, Claude Code refuses requests or bills you pay-as-you-go. The reproduction recipe and how to escape it.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
Weekly. Unsubscribe anytime.