Self-Evolving AI Agents: MiniMax M2.7 Changes Everything
MiniMax M2.7 improves its own scaffolding autonomously. What self-evolving agents mean for developers and harness engineering.

Three weeks ago, we published an article arguing that harness engineering is the most important developer skill of 2026 — that the scaffolding you build around an AI model has 2x more impact on output quality than the model itself.
Today, that thesis just evolved. Literally.
On March 19, 2026, MiniMax released M2.7 — a model they describe as "our first model deeply participating in its own evolution." That sounds like marketing. It isn't. M2.7 ran 100+ autonomous optimization rounds on its own agent harness, discovering improvements no human engineer programmed, and achieving a 30% performance boost on internal benchmarks. The model didn't just execute within its scaffolding. It rewrote its scaffolding.
Source: MiniMax M2.7 official announcement
And MiniMax isn't alone. In the past six weeks, Karpathy open-sourced autoresearch, Google DeepMind shipped AlphaEvolve, OpenAI revealed Symphony, and Sam Altman told Stanford that "current AI models are already smart enough to help discover the next architecture." Five independent signals pointing in the same direction: AI agents are learning to improve themselves.
This article traces the arc from harness engineering to self-evolving agents, breaks down what M2.7 actually did (technically, not marketing-ly), and delivers the uncomfortable analysis of what this means for your career as a developer.
"One day, frontier AI research used to be done by meat computers... That era is long gone." — Andrej Karpathy, March 2026
The Evolution Arc: Four Phases in Four Years
Before we unpack M2.7, you need the trajectory. The pace is what matters here — we're watching a phase transition happen in real time.
Phase 1: Manual Coding (2020–2023). Human writes code. Human debugs code. Human ships code. Copilot shows up in 2021 as a fancy autocomplete. The human is the entire loop.
Phase 2: Agentic Coding (2024–early 2026). The agent writes code under human supervision. Devin launches as the first "AI software engineer." Claude Code, Codex CLI, and Cursor follow. The human designs constraints (CLAUDE.md, AGENTS.md), the agent executes. This is the harness engineering paradigm: same model scores 78% or 42% depending on its harness. The harness matters more than the model.
Phase 3: Autoresearch (March 2026). The agent doesn't just follow instructions — it designs its own experiments, evaluates results, and iterates autonomously. Karpathy's autoresearch repo crystallized the pattern: ~630 lines of code, single GPU, 100+ experiments overnight. We wrote a complete tutorial on building your own autoresearch loop.
Phase 4: Self-Evolving Agents (Now). The agent doesn't just experiment on external targets — it improves its own harness. The constraints, memory, skills, and orchestration code that govern the agent's behavior are themselves targets of autonomous optimization.
This is the step MiniMax M2.7 just demonstrated. And it's the step that changes the calculus.
How Karpathy's Autoresearch Set the Stage
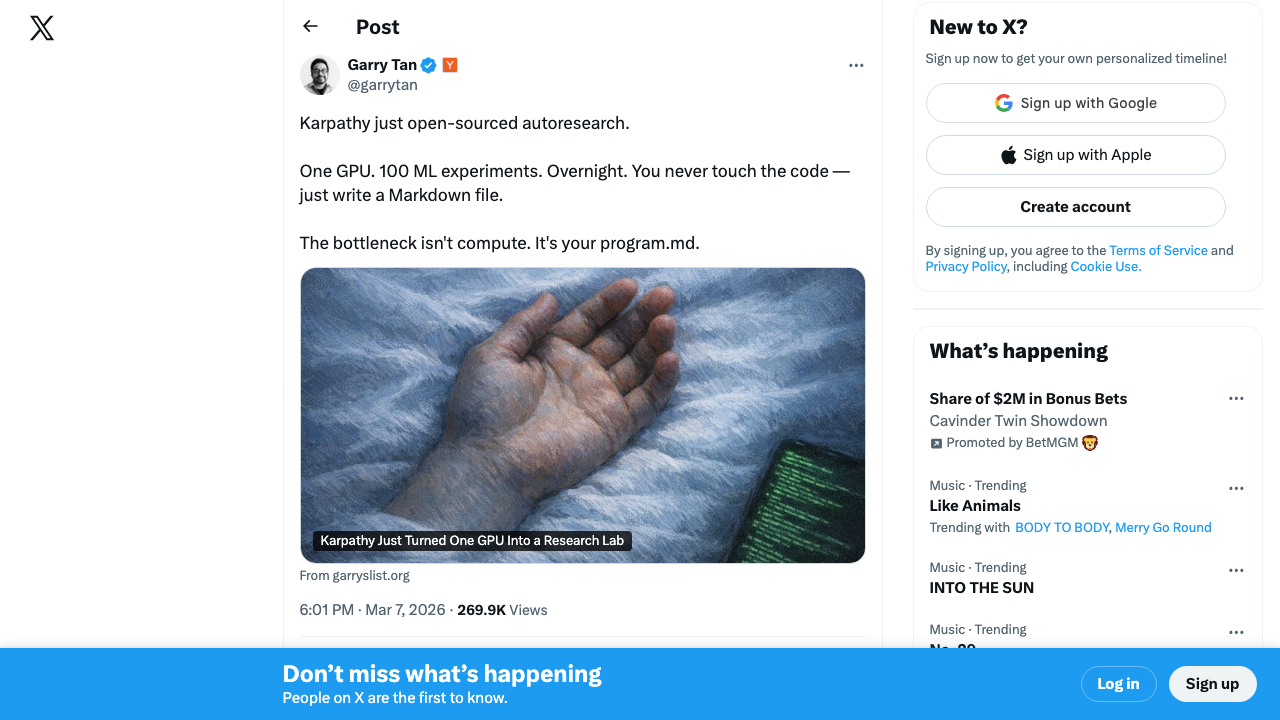
You can't understand M2.7 without understanding what came right before it. On March 7, Karpathy open-sourced autoresearch — a deceptively simple repo that automates the scientific method for ML research.
The setup: you write a program.md that defines your research direction. The agent modifies train.py, trains for 5 minutes, checks if validation loss improved, keeps or discards, and repeats. You wake up in the morning to a log of experiments and — hopefully — a better model.
Watch Greg Isenberg's breakdown of why autoresearch "broke the internet":
The community response was immediate and telling. Paul Graham retweeted. Garry Tan amplified:
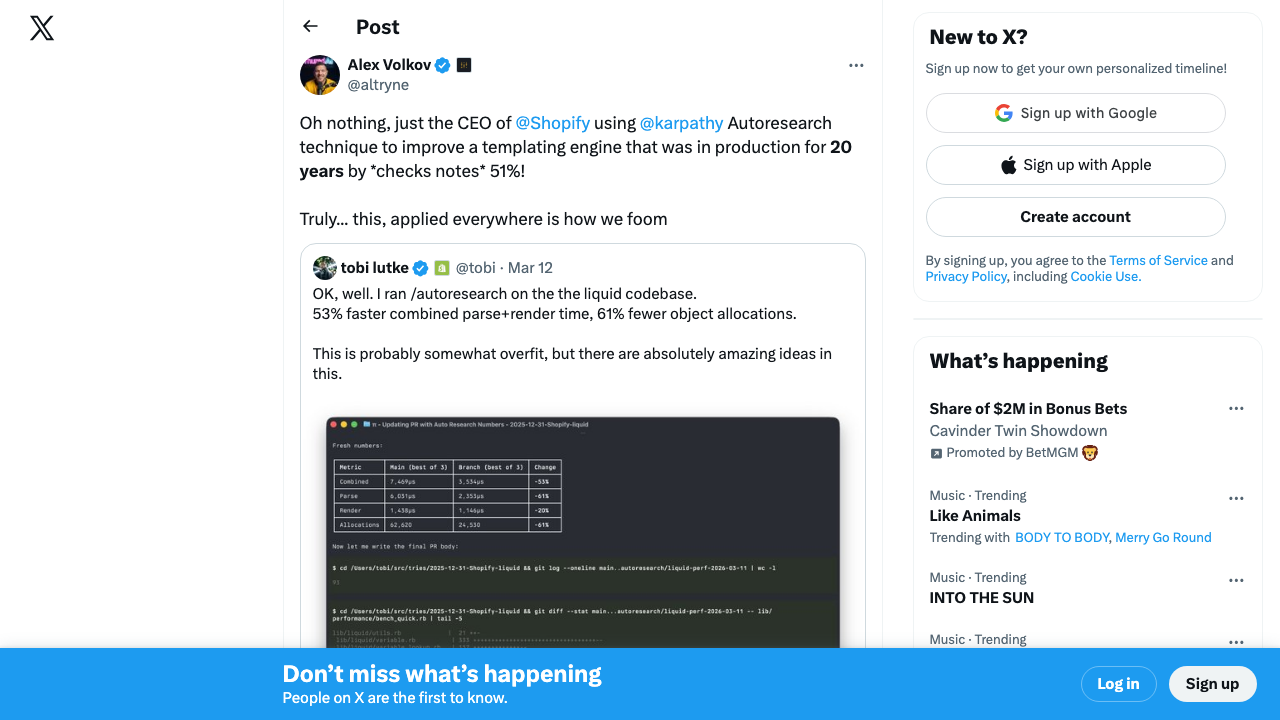
Shopify's Tobi Lütke ran it on his liquid codebase and reported 53% faster combined parse+render time and 61% fewer object allocations:
Within days, someone adapted the pattern into a live Polymarket trading bot that autonomously experiments with arbitrage strategies.
The pattern crossed from ML research to finance in under a week. That's not a tool going viral. That's a paradigm diffusing.
Here's Karpathy's original announcement — the repo that started it all:
But here's the critical limitation of autoresearch: the agent iterates on external code (train.py). It optimizes the thing it's working on, not the system it's running inside. The harness stays fixed. The human still writes program.md. The optimization loop is powerful, but it's bounded by the scaffolding around it.
M2.7 removed that boundary.
MiniMax M2.7: What Actually Happened
Let me be precise about what MiniMax built, because the term "self-evolving" carries theoretical baggage that doesn't apply here.
The Self-Evolution Loop
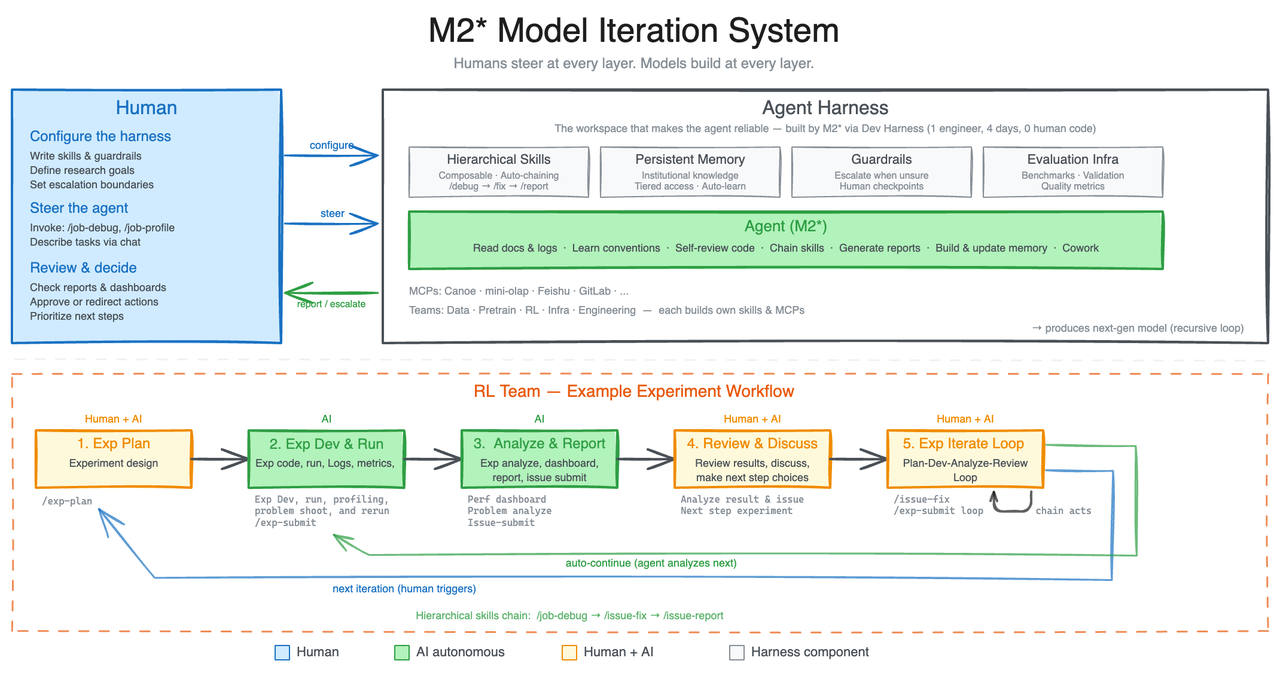
Source: MiniMax M2.7 official announcement — The architecture diagram shows the full human-AI collaboration loop, with agents handling 30-50% of the RL research workflow autonomously.
MiniMax tasked an internal version of M2.7 with a meta-challenge: build a research agent harness, use it to run RL experiments, and then improve the harness based on experiment results. Here's the cycle:
┌─────────────────────────────────────────────────┐
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ HARNESS │───▶│ EXECUTE │───▶│ EVALUATE │ │
│ │ (skills, │ │ Tasks │ │ Results │ │
│ │ memory, │ │ │ │ │ │
│ │ scaffold) │ │ │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ ▲ │ │
│ │ ┌──────────────┐ │ │
│ └───────│ MODIFY │◀───────┘ │
│ │ HARNESS │ │
│ │ (keep/revert)│ │
│ └──────────────┘ │
│ │
│ Human sets: research direction, eval │
│ criteria, safety boundaries, revert rules │
│ │
└─────────────────────────────────────────────────┘
The model's weights don't change. The training data doesn't change. What changes: the skills, the memory, the orchestration code, the prompt templates, the tool configurations, the workflow guidelines — everything in the harness layer.
This is fundamentally what a human harness engineer does. Except M2.7 ran 100+ optimization rounds. A human engineer manages maybe 5–10 harness iterations per week. The acceleration is 10–20x in iteration speed, not in cognitive capability.
What M2.7 Actually Discovered
During those 100+ autonomous rounds, M2.7 found optimizations that are impressively practical:
- Systematic parameter search: Optimal combinations of temperature, frequency penalty, and presence penalty for different task types
- Smarter workflow guidelines: After fixing a bug, automatically search for the same pattern in other files (a best practice many human engineers forget)
- Loop detection: Adding safeguards to prevent the agent from getting stuck in repetitive cycles
These aren't exotic breakthroughs. They're the kind of harness refinements a thoughtful senior engineer would make — given enough time and patience to test every combination. M2.7 had both.
The Benchmarks
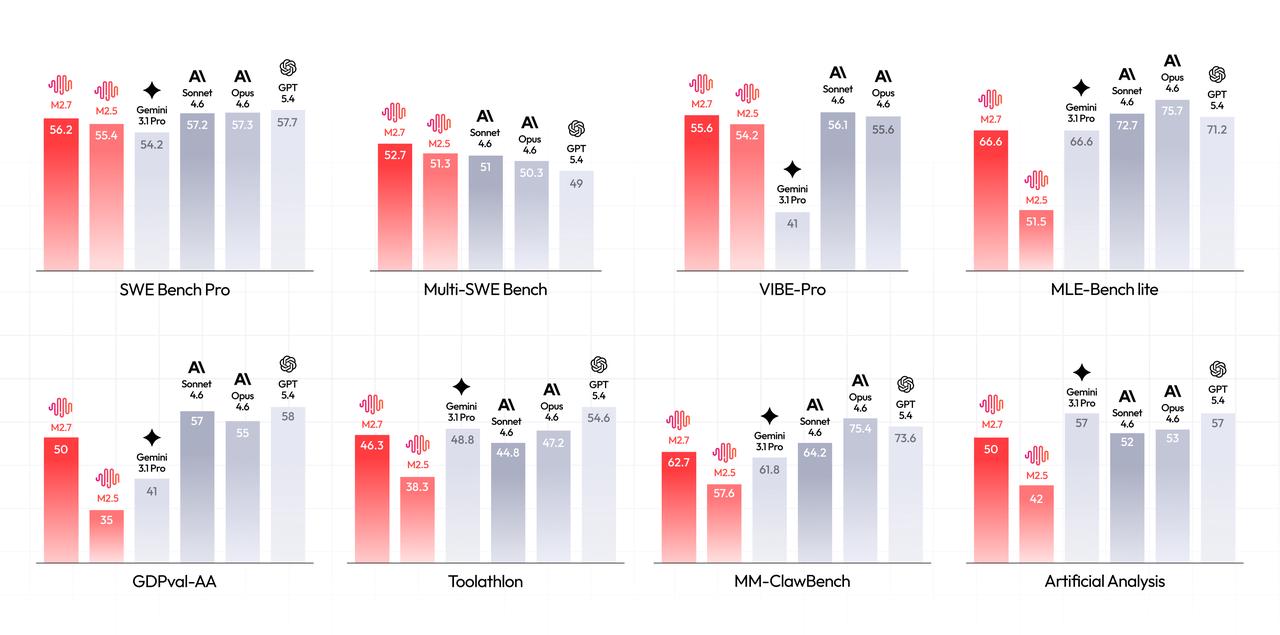
M2.7's performance tells a story about where Chinese AI labs are relative to the frontier — and it's closer than most people assume:
| Benchmark | M2.7 | Context |
|---|---|---|
| SWE-Pro | 56.22% | Matches GPT-5.3-Codex |
| VIBE-Pro | 55.6% | Near Opus 4.6 level |
| Terminal Bench 2 | 57.0% | Complex engineering systems |
| SWE Multilingual | 76.5 | Multi-language coding |
| Multi SWE Bench | 52.7 | Cross-project engineering |
| GDPval-AA ELO | 1495 | Highest among open-source models |
| Toolathon | 46.3% | Global top tier |
| MM Claw | 62.7% | Near Sonnet 4.6 |
| MLE Bench Lite | 66.6% medal rate | Ties Gemini 3.1 |
| Skill adherence | 97% | 40+ complex skills, each 2K+ tokens |
On MLE Bench, M2.7 participated in 22 machine learning competitions using a simple harness with short-term memory, self-feedback, and self-optimization modules. Best run: 9 gold, 5 silver, 1 bronze. Average medal rate across 3 trials: 66.6% — tying Gemini 3.1, behind only Opus 4.6 (75.7%) and GPT-5.4 (71.2%).
Watch this breakdown of M2.7's self-evolution mechanics and MLE Bench results:
The cost angle nobody's discussing: MiniMax offers M2.7 at roughly $10/month for individual developers. Opus 4.6 costs 10–20x that. When a $10 model achieves 97% skill adherence across 40+ complex skills, the "premium model" moat starts leaking.
Why "Self-Evolving" ≠ "Self-Aware"
I need to be direct about what this is and isn't, because the discourse is going to get breathless.
M2.7 is not improving its own weights. It's improving its own harness. This distinction matters enormously. Most discussions of "recursive self-improvement" imagine a model rewriting its own neural network — which is both technically difficult and safety-concerning. M2.7 does something subtler: it modifies the constraints, skills, memory, and orchestration code that govern how it operates. The model architecture stays fixed. The scaffolding evolves.
This is harness self-modification, not model self-modification. And it maps directly to the harness engineering paradigm we documented: the same stack we described — orchestrator, agent runtime, constraint layer, review pipeline, memory system, tool layer — is exactly what M2.7 autonomously iterates on.
The philosophical implication: if the harness matters more than the model (our central thesis), and the model can now improve its own harness, then the model is optimizing the variable with the highest leverage on its own performance. That's not a coincidence. That's the system converging on the same insight we reached through analysis.
The loop is bounded. M2.7 cannot:
- Modify its own weights
- Train a successor model from scratch
- Expand its own compute allocation
- Remove its own safety constraints
- Escape the evaluation framework humans defined
The human still controls the objective function, the safety boundaries, and the decision to deploy. This is harness self-modification within human-defined constraints.
The Convergence: Five Players, One Pattern
M2.7 didn't emerge in isolation. Five independent teams converged on self-improvement from different angles in the same six-week window. That convergence is the real signal.
Karpathy — Autonomous Experiment Loops
Human writes program.md. Agent runs experiments, evaluates, keeps/discards, repeats. The code under study is the target, not the agent itself. ~630 LOC, single GPU, 100 experiments overnight.
Significance: Proved that bounded autonomous optimization works. The minimalist design — one program file, one training script — made the pattern accessible to everyone.
OpenAI — Symphony and Episodic Memory
Full ticket-to-merge orchestration. Symphony managed 1M lines of production code, 100% agent-written. The key self-improvement angle: episodic memory that compounds over time. Agents get better at familiar task types by referencing their own successful history.
Watch OpenAI's Build Hour to see Symphony in action — particularly the episodic memory and vibecoded lints:
Google DeepMind — AlphaEvolve
Evolves the algorithms that search for solutions. Uses Gemini to mutate and improve algorithms through an evolutionary loop. Broke 5 Ramsey theory lower bounds simultaneously, one standing for 20 years.
AlphaEvolve is the closest to "genuine" recursive self-improvement in the traditional AI safety sense, but scoped to mathematical algorithm discovery rather than general intelligence. It's scientifically the most impressive. M2.7 is practically the most useful.
Deep dive into AlphaEvolve's mathematical breakthroughs:
Anthropic — Claude Code Skills Loop
Skills 2.0 introduced evals, A/B benchmarks, and skill optimization — the infrastructure for agents to iteratively improve their own capabilities. The system supports writing a skill, evaluating performance, revising, and re-evaluating. The architectural distance between "human revises skill based on eval data" and "agent revises skill based on eval data" is trivially small.
Poetiq — Reasoning Harnesses
Recursive self-improvement of prompt chains and reasoning decomposition. Topped ARC-AGI v2 without fine-tuning. Beat Claude Opus 4.6 on Humanity's Last Exam (55% vs 53.1%) for under $100K. Seven-person team. The harness evolves its reasoning strategies. The model stays the same.
The pattern across all five: Nobody is modifying model weights. Everyone is modifying the scaffolding — the skills, memory, reasoning chains, workflow guidelines, and evaluation criteria. Harness engineering was already the most important skill in AI development. Now the agents themselves have figured that out.
The Timeline: Six Weeks That Changed the Trajectory
| Date | Event | Why It Matters |
|---|---|---|
| Mar 5 | Claude Code Skills 2.0 | Skills become iterable with evals — the constraint layer is now optimizable |
| Mar 6 | Karpathy: "memory-as-tools" | 3.8K likes — proves memory is a tool the agent should manage |
| Mar 7 | Karpathy open-sources autoresearch | Autonomous ML experiment loop goes public |
| Mar 8 | Nate B Jones: "78% vs 42%" | Same model, different harness, 2x difference — harness > model confirmed |
| Mar 11 | OpenAI Build Hour reveals Symphony | 1M LOC, 100% agent-written with episodic memory |
| Mar 12 | Autoresearch derivatives emerge | Pattern crosses from ML to finance in 5 days |
| Mar 15 | We publish "Harness Engineering" | Our thesis: scaffolding > model |
| Mar 17 | AlphaEvolve breaks 5 Ramsey records | Meta-search: AI evolves the algorithms themselves |
| Mar 18 | Altman at Stanford: "recursive improvement loop" | Narrative positioning, not evidence |
| Mar 19 | MiniMax M2.7 releases | First model that participated in its own evolution |
Six weeks. From "agents write code under supervision" to "agents improve the systems that govern their own behavior." That's phase transition velocity.
The MM Claw Benchmark: Why OpenClaw Is the Standard Now
Here's a detail from the M2.7 announcement that most coverage will bury, but developers should notice: MiniMax built an evaluation set called MM Claw — explicitly based on "commonly used tasks in OpenClaw."
The benchmark covers personal learning planning, office document processing, scheduled research, investment advice, and code development. M2.7 scored 62.7%, close to Sonnet 4.6's level.
Two things matter here:
1. MiniMax is validating OpenClaw as a benchmark platform. When a major lab builds an eval based on your workflows, you've become the reference implementation for "what agents actually do in the real world." That's the strongest possible signal about where the agent ecosystem is headed.
2. The 97% skill adherence rate across 40+ complex skills (each exceeding 2,000 tokens) demonstrates that M2.7 has internalized the skill-based agent paradigm. It doesn't just follow instructions — it maintains behavioral coherence across dozens of overlapping constraint documents. This is native agent capability that can't be bolted on through prompting alone.
What Self-Evolving Agents Mean for Developers
The skill tree just forked again.
Before harness engineering (2024): Your value was in writing code.
After harness engineering (early 2026): Your value was in writing constraints that prevent bad agent code.
After self-evolving agents (now): Your value is in writing the meta-constraints — the evaluation criteria, safety boundaries, and objective functions that govern how agents improve their own constraints.
This is a higher level of abstraction. You're no longer asking "what should the CLAUDE.md say?" You're asking "what should the system that writes and evaluates CLAUDE.md files optimize for?"
Concrete example from MiniMax: Their RL team researchers now "only interact for critical decisions and discussions." The agent handles literature review, experiment specification, data pipelines, monitoring, debugging, and code fixes. The researcher's job is to evaluate whether the agent's autonomous decisions produce good research outcomes — and to course-correct the meta-parameters when they're not.
This maps to Levels 3 and 4 of the harness engineering framework from our previous article:
- Level 3: Self-improving constraint documents that update based on agent error patterns ← M2.7 demonstrates this works today
- Level 4: Agent fleet management with centralized monitoring and cost optimization ← The organizational challenge ahead
The Uncomfortable Career Question
"Don't worry, your job is safe — you'll just manage agents instead of writing code." That narrative has a shelf life.
If the harness itself is just text — and it is, CLAUDE.md is a markdown file — then the management layer isn't immune from automation. The real endgame isn't humans managing agents. It's agents managing agents, with humans setting organizational policy.
But here's the thing: that endgame is still measured in years, not months. And right now, the engineers who understand how to write evaluation criteria, design safety boundaries, and architect agent harnesses are extremely rare and extremely valuable. The window for building that expertise is open. The self-evolving agents will make it more valuable before they make it less valuable.
The Contrarian Take: This Is Better DevOps, Not AGI
Let me be direct about what self-evolving agents actually represent, because the discourse is about to oscillate between euphoria and existential dread, and both are wrong.
Self-evolving agents are not a path to AGI. They're a path to better DevOps.
M2.7's self-improvement loop is functionally identical to what a senior engineer does when they refine their team's CI/CD pipeline, update their coding standards document, and tune monitoring dashboards based on last sprint's incidents. The difference is speed and scale, not kind.
The 30% improvement from 100+ autonomous rounds? A good engineering team achieves similar improvement over a quarter of focused process optimization. M2.7 does it faster. That's valuable — enormously valuable — but it's not a qualitative leap. It's quantitative acceleration of a known process.
The real revolution isn't self-improvement. It's the democratization of process optimization.
Today, only the most sophisticated organizations have the institutional knowledge to build great agent harnesses. Self-evolving agents make that optimization accessible to everyone. Deploy M2.7 with a basic harness, and the model improves the harness for you. It's the same dynamic as cloud computing: the capability that only Google and Amazon had in 2005 became available to everyone via AWS.
The MiniMax strategy nobody's discussing: MiniMax is a Chinese lab releasing a self-evolving model at $10/month. The play isn't competing on model quality — it's competing on total cost of harness engineering. If your model improves its own harness, you need fewer human harness engineers. That reduces the talent bottleneck. And the talent bottleneck is where Western labs have a massive advantage. Self-evolving models are a talent arbitrage strategy.
The Risks Nobody Wants to Talk About
Goodhart's Law Applies With Extra Force
If the model improves its own harness, and you evaluate improvements using a metric you defined, the model will optimize for that metric. Not for what you actually want — for the metric. This is Goodhart's Law, and self-improving systems apply it recursively.
MiniMax's 30% improvement on "internal evaluation sets" sounds great. But who defined those sets? MiniMax. How do they know the improvements generalize to real-world tasks? They'll have to demonstrate that over time. A single benchmark from the team that built the system isn't evidence — it's a claim.
The Evaluation Problem Is Circular
If the model improves its own harness, and you evaluate the improvement using the model's own outputs, you have a circular evaluation problem. MiniMax addresses this with human-in-the-loop "critical decisions," but as the system gets more autonomous, human checkpoints become sparser.
The Competitive Pressure Is Destabilizing
If self-improvement loops produce compounding advantages, the lab with the fastest loop speed wins everything. This creates intense pressure to reduce human oversight (because humans are the bottleneck) and increase autonomy (because autonomous iteration is faster). The incentive structure pushes toward less safety, not more.
What to Do Monday Morning
The theory is interesting. But you're a developer. Here's what to actually do.
This week: Instrument your harness for self-evaluation. If you have a CLAUDE.md or AGENTS.md file, start logging when agent outputs succeed and when they fail. Track which constraint clauses correlate with good outcomes. You can't improve what you don't measure — and you can't automate improvement without measurable signals.
This month: Build an A/B testing loop for your constraints. Try variant A of a constraint for a week, variant B the next week, and compare outcomes on the same task types. This is manual autoresearch applied to your own harness. It's the exact process M2.7 automated — you're just doing it at human speed with human judgment.
This quarter: Identify which harness components are candidates for agent-driven optimization. Temperature settings, tool selection heuristics, prompt templates, workflow sequencing — these are all parameters a model could search over if given the right eval criteria. Start defining the eval criteria now, even if you're not ready to automate the optimization.
Ongoing: Watch the DeerFlow ecosystem. ByteDance's DeerFlow 2.0 and MiniMax's M2.7 are converging from different directions on the same architecture: skill-based harnesses with persistent memory, sandbox execution, and autonomous self-improvement. DeerFlow provides the runtime; M2.7 demonstrates the model that can evolve within it. If you want a complete agent harness to experiment with, DeerFlow or OpenClaw are your best starting points.
My Predictions: Where I'm Placing Bets
Within 6 months: Every major agent platform will ship native "self-improvement mode" — the agent suggests and A/B tests improvements to its own skills and configuration. Too obvious and too easy not to happen.
Within 12 months: "Self-improving harness" becomes a product category. Companies will sell pre-optimized, self-evolving agent harnesses for specific industries. The harness itself becomes the product, not the model.
The safety line is at Step 3. Harness self-modification (Step 2) is safe and bounded. When systems start modifying their own evaluation criteria — deciding for themselves what "good" means — that's when the debates become urgent. We're not there yet. But the path from Step 2 to Step 3 is shorter than people think.
MiniMax's approach beats AlphaEvolve for real-world utility. AlphaEvolve is scientifically more interesting. M2.7 is practically more useful. The market rewards practical utility.
The "self-evolving" label will be co-opted within 90 days. Expect every model release to claim "self-improvement capabilities" regardless of substance. The signal-to-noise ratio on this topic will degrade rapidly.
The Bottom Line
Three weeks ago, the harness mattered more than the model.
Today, the models are learning to build their own harnesses.
This doesn't invalidate harness engineering. It elevates it. The human's role shifts one level up: from designing harnesses to designing the constraints and evaluation criteria that govern how harnesses self-improve. The meta-harness.
The evolution arc is clear:
- 2024: Human writes code → agent assists
- 2025: Human writes constraints → agent writes code
- 2026 Q1: Human writes research agenda → agent runs experiments
- 2026 Q2: Human writes evaluation criteria → agent improves its own harness
Each step moves the human up one level of abstraction. Each step gives the agent more autonomy. Each step is bounded by the level above it.
MiniMax M2.7 is the first production-grade demonstration that this works. It won't be the last. The question isn't whether self-evolving agents are real — they are. The question is whether the human-defined boundaries hold as the loops get faster and the improvements compound.
I think they will. But I'd feel better about that prediction if more people were asking the question.
This is part of our ongoing coverage of AI agent development. For the foundational framework, read "Harness Engineering: The Developer Skill That Matters More Than Your AI Model." For a hands-on tutorial, see "Build an AI Research Agent with the Autoresearch Pattern."
About ComputeLeap Team
The ComputeLeap editorial team covers AI tools, agents, and products — helping readers discover and use artificial intelligence to work smarter.
💬 Join the Discussion
Have thoughts on this article? Discuss it on your favorite platform:
Related Articles
Inside the Claude Code Post-Mortem: 50+ Fixes, Verified
Anthropic shipped 50+ fixes across four CLI releases. We group them by category and give you a 5-minute self-test to verify the rebound.
Claude Code Charges Extra for 'OpenClaw' Git Commits
If your git history mentions OpenClaw, Claude Code refuses requests or bills you pay-as-you-go. The reproduction recipe and how to escape it.
OpenAI Killed the Codex Model Line: What It Means for Devs
OpenAI confirms there's no GPT-5.5-Codex. Here's what changes for devs who built around the Codex tier — and where third-party skills fill the gap.
The ComputeLeap Weekly
Get a weekly digest of the best AI infra writing — Claude Code, agent frameworks, deployment patterns. No fluff.
Weekly. Unsubscribe anytime.